Multi-Agent Screen Region Reader
Teaching Hellbot to Read…
When I previously talked about the budding GPT Vision Endpoint in November 2023, I had a few ideas on how to leverage it to “augment” my Twitch Streaming experience by having it react to things happening in game. This was a pretty generic idea without a lot of depth, and while it did have the effects I was looking for (making fun of me, adding chaos), it didn’t leverage the full utility of an Image Recognition platform.
OCR, CohhCarnage, and Hellbot
When CohhCarnage tweeted:
When I play massive cRPGs without voice acting, it destroys my voice. I'm basically just reading out loud for hundreds of hours.
— Cohh Carnage (@CohhCarnage) January 22, 2024
I'd like to make an AI version of my own voice to use with OCR so I can drag a box around text and my own AI voice reads it.
Where do I get started?
Between ChatGPT+ElevenLabs, I knew I had everything in place to make it happen. A few hours later, I had ChatGPT reading the text from screenshots, and was feeding that output into ElevenLabs API. It felt great to hear Sheogorath say the words I was typing on screen. It was also VERY slow. Between a ~5 second call to ChatGPT and ~5 second call to ElevenLabs to process the TTS, it wasn’t very usable.
Speeding Up By Streaming
ElevenLabs Offers both a streaming API and a Websocket to stream partial responses before they are full rendered in an Mp3.
By sidechaining their Python solution with some Windows task magic (I launched a Command Prompt which ran a Python script.), which in turn uses MPV to play the audio stream, I had a working implementation in only a few minutes. Well, after I spent about 3 hours trying to do it myself. The lesson: Why spend time solving a problem that has already been solved?
With this solution, the TTS started playing in only a few hundred milliseconds. A drastic improvement over the 5-10 seconds for the API.
Screen Regions over Screens
In a Video Game especially, and in most applications, webpages, etc. there is a ton of text that isn’t necessary information. Menus, navigations, CTAs, instructions all fill the sides of the screen and can make screenreaders feel robotic, verbose, and confusing.
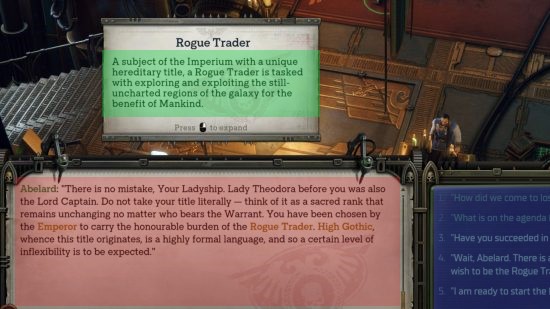
Consider the following screenshot from OwlCat’s recent release, Rogue Trader:

There are clearly 3 distinct areas for text to be read from. Different areas, different context, read in different ways subconsciously.
- The top box, a tooltip, giving additional lore, read as a 3rd person narrator.
- The bottom left box, dialogue from a character named Abelard, read in their voice.
- The bottom right box, containing player dialogue choices, read in the voice of your character.
Reading them all at once would not only be long, but could break context if read in the wrong order. We need a way to select only the screen region we want to read. In Rogue Trader, and many other games, this is a static box in which in-game character text is placed.
Multiple Screen Regions, Multiple Agents
Once we can select one screen region and read it in an Agent’s voice, there’s little stopping us from replicating this as many times as we want.
Each screen region can be hooked to a different voice to give a more dynamic and immersive experience.
But we don’t have to stop there…